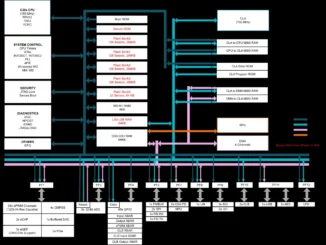
Der Fachbeitrag von Mathworks, erschienen in der Fachzeitschrift Elektronik Praxis, beschreibt, wie sich Edge-KI-Anwendungen durch den gezielten Einsatz von Neural Processing Units (NPUs) und Modellkompression für Echtzeit- und Embedded-Systeme optimieren lassen. Ausgangspunkt ist die wachsende Bedeutung von Edge-KI, bei der Entscheidungen direkt auf dem Gerät getroffen werden müssen, häufig unter strengen Randbedingungen hinsichtlich Latenz, Energieverbrauch und Speicher. Als Beispiel wird unter anderem die Motorsteuerung genannt, bei der Inferenzzeiten unter 10 ms erforderlich sind. Gleichzeitig macht der Artikel deutlich, dass NPUs nur dann ihr Potenzial entfalten, wenn die KI-Modelle an die begrenzten Ressourcen angepasst werden.
Den Kern des Beitrags bilden zwei Kompressionstechniken: Projektion und Quantisierung, die eingehend vorgestellt werden. Die Projektion reduziert die Modellkomplexität auf struktureller Ebene, indem redundante Parameter entfernt werden, beispielsweise auf Basis der Hauptkomponentenanalyse. Die Quantisierung reduziert anschließend den Speicher- und Rechenaufwand weiter, indem Gleitkommawerte in niedrigpräzise Ganzzahlformate überführt werden. In Kombination lassen sich so Modelle deutlich verkleinern und beschleunigen, ohne die Genauigkeit stark zu beeinträchtigen, so die Kernaussage.
Der Beitrag zeigt einen konkreten, praxisnahen Weg auf, wie KI-Modelle realistisch auf Embedded- und NPU-Hardware gebracht werden können. Er verdeutlicht die notwendigen Abwägungen zwischen Genauigkeit, Laufzeit und Ressourcenbedarf und gibt Hinweise zu Workflows, die sich bewährt haben. Nicht behandelt werden Aspekte wie Safety- und Zertifizierungsanforderungen (z. B. ISO 26262), der Vergleich unterschiedlicher NPU-Architekturen oder Laufzeit-Frameworks sowie konkrete Zahlen zu Performance-Gewinnen im Serieneinsatz. Auch Grenzen der vorgestellten Methoden bei sehr großen Modellen oder multimodalen Netzen werden nicht diskutiert. (oe)